
Synthetic data alone is not enough

Is AI-generated synthetic data a privacy cure-for-all? In the second article of our Re:defining trust series we explore synthetic data's benefits, shortcomings, and we propose a way to get the best of both worlds.
A year ago, Gartner predicted that, in 2024, 60% of data use for AI development and analytics project will be synthetically generated. With two years to go, where are we standing? The trend is definitely there, but in the course of creating production deployments of analytics products based on synthetic data, we found out that the reality is more complicated.
What is synthetic data anyway?
The European Data Protection Supervisor defines synthetic data generation as “to take an original data source (dataset) and create new, artificial data, with similar statistical properties from it”. This is an example of a privacy-enhancing technology (PET) that can offer multiple benefits. First of all, it is a powerful tool for data analysis and modeling, since data scientists can interact with data that “looks real” and is easy to use, but is not based on any particular original individual data point.
Synthetic data comes in as many varieties as there are dataset types, but for this blog we will focus on synthetic structured data. This type of synthetic data is commonly presented as the “best of both worlds” when it comes to data privacy and security for analytics and AI on sensitive data. And why not? Data scientists get to keep all their processes and workflows and the data owners get to keep their original data and their users’ privacy. How is that possible? To answer that, we first need to a high level understanding of current synthetic data generation processing.
To generate synthetic data, you first need to train a machine learning model on the original data. That model learns patterns and statistical distributions from the underlying data. The model can then generate as many rows as you need to do analysis or train a different model, with the correct statistical relationships and patterns. Of course, doing that is not trivial, and that is why there are a lot of startups and established companies investing in this technology to find the best possible models for generating synthetic datasets.
But what are the dimensions that a synthetic data model (or a synthetic dataset) should be evaluated upon? In the case of sensitive data, we argue there are two chief concerns:
- How useful or accurate this data is for getting novel insights (utility)
- What is the probability that someone who can see the dataset can learn sensitive information about the original data (privacy)
Beware of PETs bearing gifts
Searching around the web could lead someone come to believe that synthetic data combines high privacy and utility in a convenient and portable format. This can be true in some cases, we found out that there are certain caveats that are easy to overlook, but become crucial for understanding the benefits of a production system.
Not an anonymization free-pass
There is usually an inherent tradeoff between privacy and utility — more and more accurate information leads to more utility, but gives more chances to reveal information that compromises privacy. Any person who dealt with sensitive data knows that the more you try to anonymize a dataset, the less useful it is. PETs are not immune to this tradeoff, but may offer a more advantageous exchange rate. It is not surprising that this dynamic exists for synthetic data as well [1, 2]. AI-generated synthetic data is not automatically anonymous, and using AI-synthetic data generators does not necessarily fulfil the strict anonymization requirements of GDPR.
Synthetic data is still extremely attractive for overall usability, since it provides individual-level rows that can be used the same way as any other dataset. This is much easier than relying on aggreged data that can break existing schemas and force a change in workflows.
Model of a model
Now that we know synthetic data is generated by an AI model trained on the original data, an additional tradeoff is surfacing. If you build a model or analysis on top of the synthetic, it’s a bit like making a copy of a copy. It is possible to get accurate results with a synthetic data model that has been carefully hand tuned for an exact purpose by experts, but it’s easy to end up with a copy of a copy that has significantly reduced utility. Any analysis coming from the output of a synthetic data generator will be (at best) as good as the model that generated the data. This is the place where multiple vendors are working on, but we’ve seen that domain expertise and a lot of time is required in practice; especially when you factor in the privacy aspect [3].
Hard to JOIN
While synthetic data for a single data source is great, when it comes to joining multiple datasets sitting on different locations it suddenly becomes much harder. Since the data is synthesized and masked, any index keys you might use to join together two data sets, like an email address or a customer ID, won’t match or line up with real data. This means that if you want to collaborate by joining synthesize data that comes from different sources, you will need to coordinate their synthesis process so they will match enough for you to perform joins — a tricky feat of operational coordination.
Deployment and trust
One of the main arguments for using PETs is of course that the data owner is not revealing to anyone their sensitive data; while still learning useful information. For most of the organizations we speak to, “anyone” usually includes the software provider (the synthetic data company in that case) but also, in many cases, the cloud provider.
So if these organizations want to make sure that their data is not visible to the synthetic data model vendor or the cloud provider they have to deploy the synthetic data software on their premises, with all the scalability and cost problems that this entails. At least, this is where they control the data while in-use. Making sure that the software is not leaking information during the compute to a SaaS provider or to a cloud admin.
The best of all three worlds
While synthetic data shortcomings may be hindering its mass adoption, organizations using our platform have found it extremely valuable. Since sensitive data is already difficult to access, providing frictionless workflows is crucial to ensure new projects actually begin. So we set out to improve it.
We created a unique value proposition for synthetic data generation by drawing on the security of confidential computing in our data clean rooms to mitigate the limitations of synthetic data.
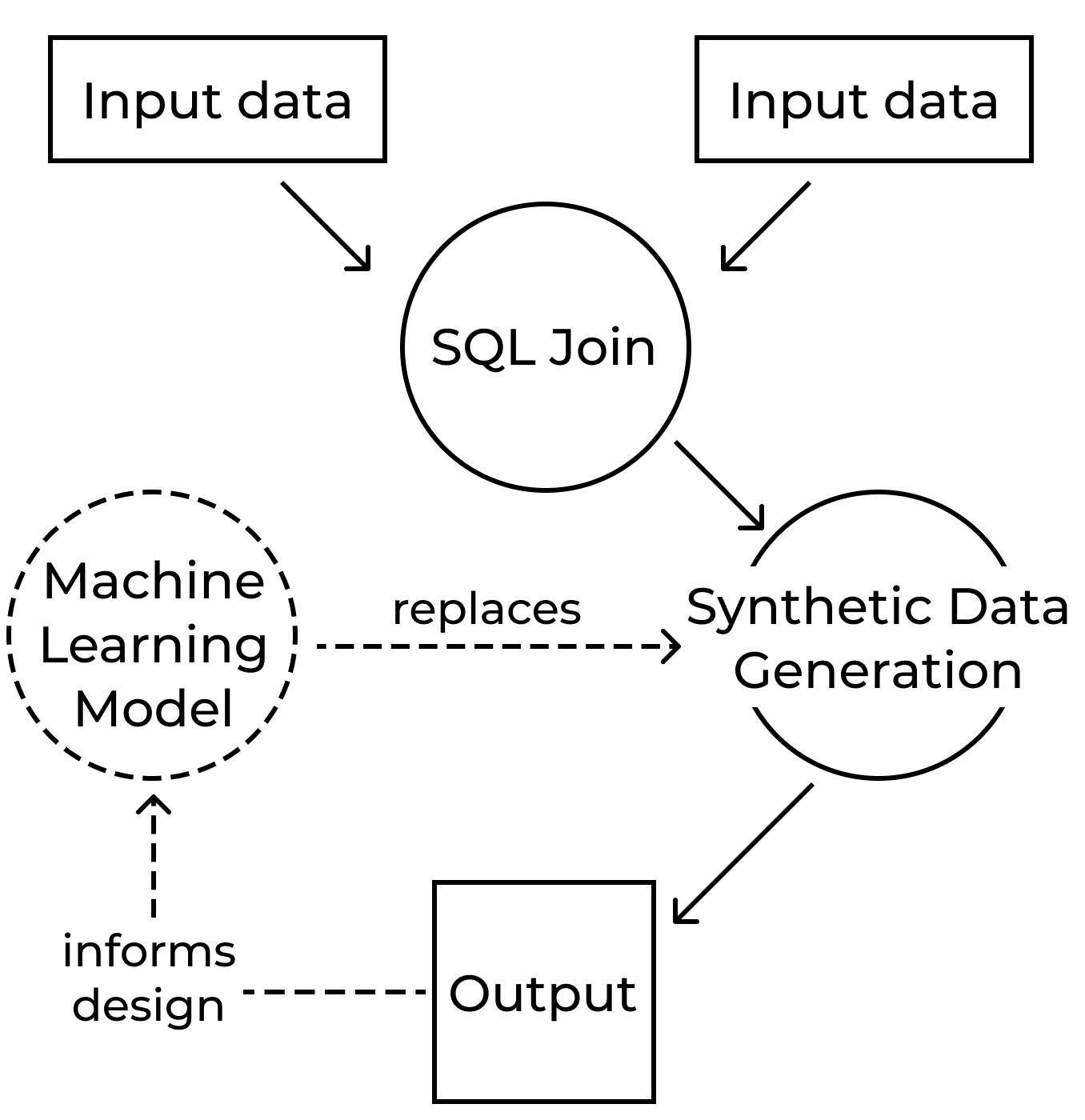
- Ability to join data before synthesis: Decentriq’s data clean rooms are built on top of confidential computing technology, one of the most powerful and secure ways to collaborate on data without sharing it. Essentially in our Confidential Data Clean room organizations are able to join their datasets before they synthesize — creating synthetic data that is both more accurate, and operationally easier because different data owners don’t need to coordinate in advance to have consistent join keys. It also provides the highest level of privacy, since individually identifying join keys never need to leave the clean room, even pseudonymously.
- Increased accuracy of final model or analysis: Since the original data is available in the Confidential Data Clean room, once a data scientist has perfected their modeling approach on the synthetic data, they can then deploy it on the original raw data. This will almost always be more accurate than trying to train a model on top of modeled data. You can now tune a model on synthetic data, but then train on and get results from the real data.
- This approach allows us to be much more strict with privacy than any model which aims to generate synthetic data output for novel analytic insights. Because we know that the final analysis will be done on the real data, we afford to sacrifice utility for the sake of privacy and provide synthetic data with very strict privacy guarantees.
Scalable trust
Since our data clean rooms run in confidential computing it means that the raw sensitive data is encrypted to everyone at all times. Including Decentriq and the cloud provider. Effectively this mean that the whole collaboration workflow can be served as a scalable cloud SaaS while giving all the security guarantees of running on-prem. If you want to learn more about how confidential computing works in our platform you can request our thorough technical whitepaper.
Building trust in privacy decisions
We at Decentriq believe that promising privacy silver bullets in an environment where de-identification attacks and data breaches are commonplace is only eroding trust in privacy-enhancing technologies as a whole. We instead try to to build trust with our users when they open their most sensitive data for analysis by offering easy to understand choices and transparent rules. That is why, not only we offer transparent and easy to understand options in synthetic data generation coming from open-source projects, but we also make sure that the data owners always have the final say over what is happening on their data. If you are interested in learning more, our whitepaper offers a good picture of how security and control are implemented, while in a future blog we will expand more on the synthetic data generators that we evaluated, the tradeoffs that we choose, and why. For the first article of our Re:defining trust series around Differential Privacy as a way to protect first-party data click.
References
Related content
.jpg)


Subscribe to Decentriq
Stay connected with Decentriq. Receive email notifications about industry news and product updates.